Basis for Intentions: Efficient Inverse Reinforcement Learning using Past Experience
Abstract
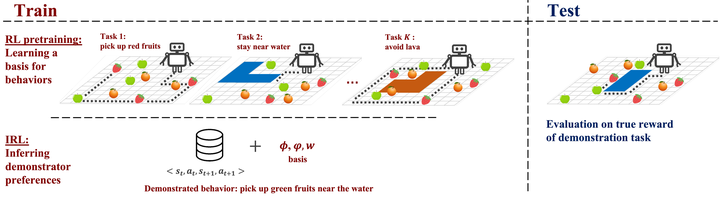
This paper addresses the problem of inverse reinforcement learning (IRL) – inferring the reward function of an agent from observing its behavior. IRL can provide a generalizable and compact representation for apprenticeship learning, and enable accurately inferring the preferences of a human in order to assist them. However, effective IRL is challenging, because many reward functions can be compatible with an observed behavior. We focus on how prior reinforcement learning (RL) experience can be leveraged to make learning these preferences faster and more efficient. We propose the IRL algorithm BASIS (Behavior Acquisition through Successor-feature Intention inference from Samples), which leverages multi-task RL pre-training and successor features to allow an agent to build a strong basis for intentions that spans the space of possible goals in a given domain. When exposed to just a few expert demonstrations optimizing a novel goal, the agent uses its basis to quickly and effectively infer the reward function. Our experiments reveal that our method is highly effective at inferring and optimizing demonstrated reward functions, accurately inferring reward functions from less than 100 trajectories.
Natasha Jaques
My research is focused on Social Reinforcement Learning–developing algorithms that use insights from social learning to improve AI agents’ learning, generalization, coordination, and human-AI interaction.