Abstract
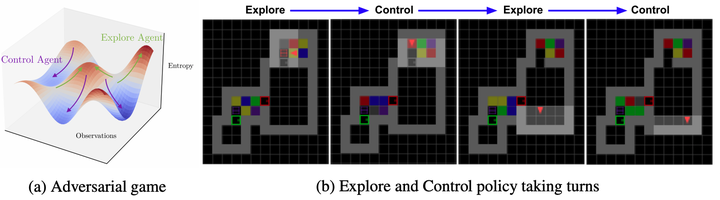
Reinforcement learning (RL) provides a framework for learning goal-directed policies given user-specified rewards. However, since rewards can be sparse and task-specific, we are interested in the problem of learning without rewards, where agents must discover useful behaviors in the absence of domain-specific incentives. Intrinsic motivation is a family of unsupervised RL techniques which develop general objectives for an RL agent to optimize that lead to better exploration or the discovery of skills. In this paper, we propose a new unsupervised RL technique based on an adversarial game which pits two policies against each other to compete over the amount of surprise an RL agent experiences. The policies each take turns controlling the agent. The Explore policy maximizes entropy, putting the agent into surprising or unfamiliar situations. Then, the Control policy takes over and seeks to recover from those situations by minimizing entropy. The game harnesses the power of multi-agent competition to drive the agent to seek out increasingly surprising parts of the environment while learning to gain mastery over them, leading to better exploration and the emergence of complex skills. Theoretically, we show that under certain assumptions, this game pushes the agent to fully explore the latent state space of stochastic, partially-observed environments, whereas prior techniques will not. Empirically, we demonstrate that even with no external rewards, Adversarial Surprise learns more complex behaviors, and explores more effectively than competitive baselines, outperforming intrinsic motivation methods based on active inference, novelty-seeking (Random Network Distillation (RND)), and multi-agent unsupervised RL (Asymmetric Self-Play (ASP)).
Natasha Jaques
My research is focused on Social Reinforcement Learning–developing algorithms that use insights from social learning to improve AI agents’ learning, generalization, coordination, and human-AI interaction.