Natasha Jaques
Natasha Jaques
Awards
Press
Featured
Publications
Topics
Talks
Communities
Light
Dark
Automatic
Deep Learning
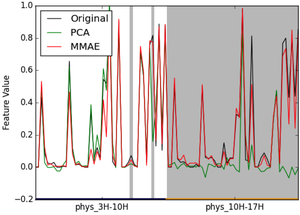
Multimodal Autoencoder: A Deep Learning Approach to Filling in Missing Sensor Data and Enabling Better Mood Prediction
Predicting signals like stress and health depends on collecting noisy data from a number of modalities, e.g. smartphone data, or physiological data from a wrist-worn sensor. Our method can continue making accurate predictions even when a modality goes missing; for example, if the person forgets to wear their sensor.
Natasha Jaques
,
S. Taylor
,
A. Sano
,
R. Picard
2017
In
International Conference on Affective Computing and Intelligent Interaction (ACII)
PDF
Cite
Code
Slides
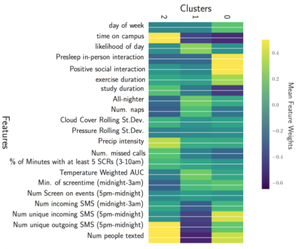
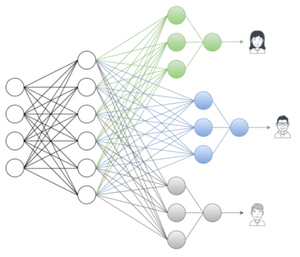
Personalized Multitask Learning for Predicting Tomorrow's Mood, Stress, and Health
Traditional, one-size-fits-all machine learning models fail to account for individual differences in predicting wellbeing outcomes like stress, mood, and health. Instead, we personalize models to the individual using multi-task learning (MTL), employing hierarchical Bayes, kernel-based and deep neural network MTL models to improve prediction accuracy by 13-23%.
Natasha Jaques
*
,
S. Taylor
*
,
E. Nosakhare
,
A. Sano
,
R. Picard
2017
In
IEEE Transactions on Affective Computing (TAFFC)
Best Paper
;
NeurIPS Machine Learning for Healthcare (ML4HC) Workshop
Best Paper
Cite
Code
Video
ML4HC Best Paper
TAFFC Journal Best Paper
Predicting Tomorrow’s Mood, Health, and Stress Level using Personalized Multitask Learning and Domain Adaptation
Modeling measures like mood, stress, and health using a monolithic machine learning model leads to low prediction accuracy. Instead, we develop personalized regression models using multi-task learning and Gaussian Processes, leading to dramatic improvements in next-day predictions.
Natasha Jaques
,
O. Rudovic
,
S. Taylor
,
A. Sano
,
R. Picard
2017
In
Proceedings of Machine Learning Research
PDF
Cite
Slides
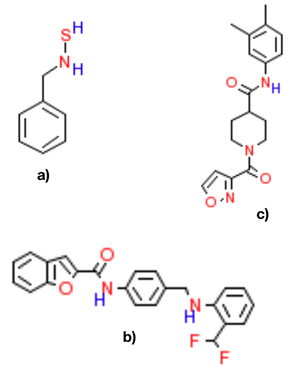
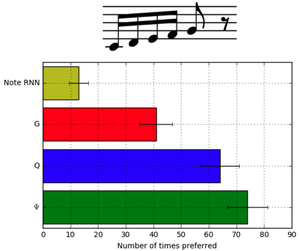
Sequence Tutor: Conservative Fine-Tuning of Sequence Generation Models with KL-control
To combine supervised learning on data with reinforcement learning, we pre-train a supervised data prior, and penalize KL-divergence from this model using RL training. This enables effective learning of complex sequence-modeling problems for which we wish to match the data while optimizing external metrics like drug effectiveness. The approach produces compelling results in the disparate domains of music generation and drug discovery.
Natasha Jaques
,
S. Gu
,
D. Bahdanau
,
J. M. Hernandez-Lobato
,
R. E. Turner
,
D. Eck
2017
In
International Conference on Machine Learning (ICML)
PDF
Cite
Code
ICML talk
Generated music
Magenta blog
MIT Tech Review article
Interactive Musical Improvisation with Magenta
This demo deployed RL Tuner and other Magenta music generation models into an interactive interface in which users can collaborate creatively with a machine learning model. The interface supports call and response interaction, automatically generating an accompaniment to the user’s melody, or melody morphing: responding both with variations on the user’s melody and a bass accompaniment.
A. Roberts
,
J. Engel
,
C. Hawthorne
,
I. Simon
,
E. Waite
,
S. Oore
,
Natasha Jaques
,
C. Resnick
,
D. Eck
2016
In
Neural Information Processing Systems (NeurIPS)
Best Demo
Cite
Code
Video
NeurIPS Demo
Magenta
Blog post
Tuning Recurrent Neural Networks with Reinforcement Learning
Generating music using traditional supervised sequence models suffers from known failure modes, including the inability to produce coherent global structure. Music is an interesting sequence generation problem, because musical compositions adhere to known rules. We impose these rules with a novel algorithm combining RL and supervised learning.
Natasha Jaques
,
S. Gu
,
R. E. Turner
,
D. Eck
2016
In
International Conference on Learning Representations (ICLR) - workshop
PDF
Cite
Code
Magenta blog
MIT Tech Review article
Understanding and Predicting Bonding in Conversations Using Thin Slices of Facial Expressions and Body Language
Given only one-minute slices of facial expressions and body language, we use machine learning to accurately predict whether two humans having a conversation will bond with each other. We analyze factors which lead to bonding and discover that synchrony in body language and appropriate, empathetic facial expressions lead to higher bonding.
Natasha Jaques
,
D. McDuff
,
Y. K. Kim
,
\& Picard R. Picard R
2016
In
Intelligent Virtual Agents (IVA)
PDF
Cite
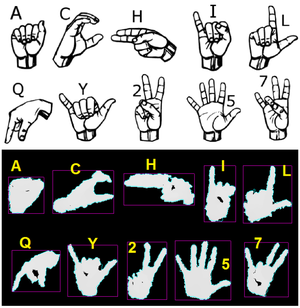
A Comparison of Random Forests and Dropout Nets for Sign Language Recognition with the Kinect
We conduct a study in which participants form American Sign Language hand signs while being recorded with a Microsoft Kinect. The resulting infra-red distance data are used to train both neural networks with dropout (dropout NN) and Random Forests; dropout NN perform significantly better.
Natasha Jaques
,
J. Nutini
2013
In
Unpublished manuscript
PDF
Cite
«
Cite
×