Natasha Jaques
Natasha Jaques
Awards
Press
Featured
Publications
Topics
Talks
Communities
Light
Dark
Automatic
Embodied AI
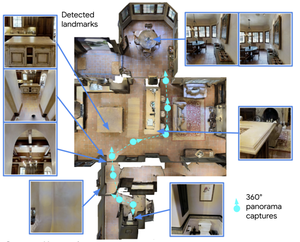
Less is More: Generating Grounded Navigation Instructions from Landmarks
We study the automatic generation of natural language navigation instructions in visually realistic indoor environments. Existing generators suffer from poor visual grounding, skip steps, and hallucinate objects. We address this using a large language model which incorporates visual landmark detection.. The model dramatically increases the quality of generated instructions, such that humans can follow them with a 71% success rate (SR); just shy of the 75% SR of real human instructions.
S. Wang
,
C. Montgomery
,
J. Orbay
,
V. Birodkar
,
A. Faust
,
I. Gur
,
Natasha Jaques
,
A. Waters
,
J. Baldridge
,
P. Anderson
2022
In
Computer Vision and Pattern Recognition (CVPR)
PDF
Cite
Dataset
Cite
×