Abstract
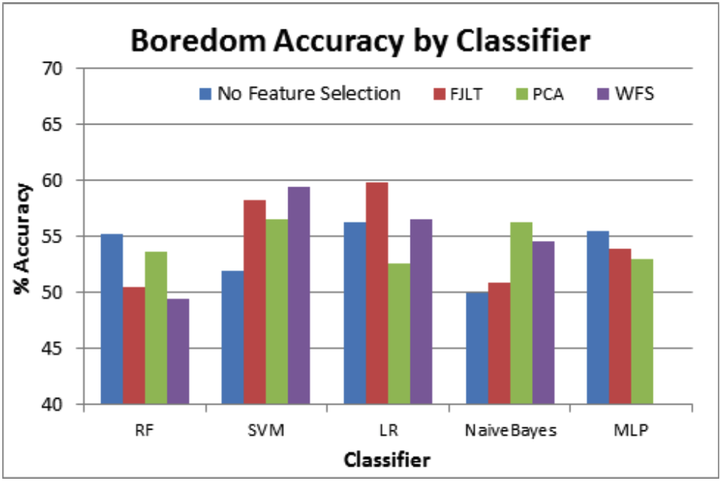
Classification of high-dimensional data presents many difficulties; not only do classifiers tend to overfit the data, especially when the number of sample points is low, but the computational complexity of many algorithms renders classification of such data prohibitive. Feature reduction techniques such as Principal Component Analysis can help to alleviate these problems, but can themselves be time consuming or ineffective. This paper presents the results of applying an efficient version of the Johnson-Lindenstrauss (JL) embedding known as the fast JL transform in order to reduce the dimensionality of two datasets before classification. We show that this simple random projection technique can offer performance that is highly competitive with existing feature reduction methods, and enable the classification of high-dimensional data using computationally complex algorithms.
Natasha Jaques
My research is focused on Social Reinforcement Learning–developing algorithms that use insights from social learning to improve AI agents’ learning, generalization, coordination, and human-AI interaction.