Natasha Jaques
Natasha Jaques
Awards
Press
Featured
Publications
Topics
Talks
Communities
Light
Dark
Automatic
Multi-Agent
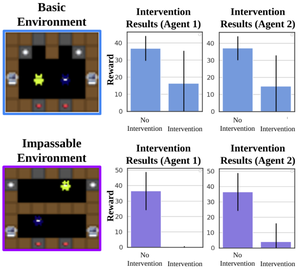
Concept-based Understanding of Emergent Multi-Agent Behavior
Interpreting whether multi-agent reinforcement learning (MARL) agents have successfully learned to coordinate with each other, versus finding some other way to exploit the reward function, is a longstanding problem. We develop a novel interpretability method for MARL based on concept bottlenecks, which enables detecting which agents are truly coordinating, which environments require coordination, and identifying lazy agents.
N. Grupen
,
Natasha Jaques
,
B. Kim
,
S. Omidshafiei
2022
In
Preprint
Cite
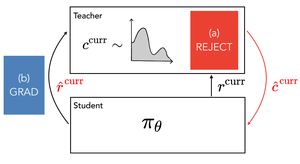
In the ZONE: Measuring difficulty and progression in curriculum generation
Past work on curriculum generation in RL has focused on training a teacher agent to generate tasks for a student agent that accelerate student learning and improve generalization. In this work, we create a mathematical framework that formalizes these concepts and subsumes prior work, taking inspiration from the psychological concept of the Zone of Proximal Development. We propose two new techniques based on rejection sampling and maximizing the student’s gradient norm that improve curriculum learning.
R. E. Wang
,
J. Mu
,
D. Arumugam
,
Natasha Jaques
,
N. Goodman
2022
In
Preprint
Cite
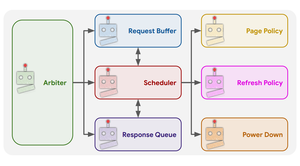
Multi-Agent Reinforcement Learning for Hardware Architecture Search: A Case Study on Domain-Specific DRAM Memory Controller Design
Reinforement Learning can potentially be a powerful tool for solving complex combinatorial optimization problems, such as microprocessor desgin. Here, we show that a multi-agent RL approach outperforms past work using single agent RL, since the problem can easily be decomposed into designing independent sub-systems.
S. Krishnan
,
Natasha Jaques
,
S. Omidshafiei
,
D. Zhang
,
I. Gur
,
V. J. Reddi
,
S. Faust
2022
In
Preprint
Cite
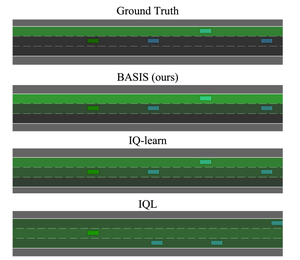
Basis for Intentions: Efficient Inverse Reinforcement Learning using Past Experience
Using inverse reinforcement learning to infer human preferences is challenging, because it is an underspecified problem. We use multi-task RL pre-training and successor features to learn a strong prior over the space of reasonable goals in an environment—which we call a
basis
—that enables rapidly inferring an expert’s reward function in only 100 samples.
M. Abdulhai
,
Natasha Jaques
,
S. Levine
2022
In
Preprint
PDF
Cite
Code
Project
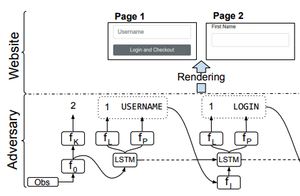
Environment Generation for Zero-Shot Compositional Reinforcement Learning
We analyze and improve upon PAIRED in the case of learning to generate challenging compositional tasks. We apply our improved algorithm to the complex task of training RL agents to navigate websites, and find that it is able to generating a challenging curriculum of novel sites. We achieve a 4x improvement over the strongest web navigation baselines, and deploy our model to navigate real-world websites..
I. Gur
,
Natasha Jaques
,
K. Malta
,
M. Tiwari
,
H. Lee
,
A. Faust
2021
In
Neural Information Processing Systems (NeurIPS)
PDF
Cite
Code
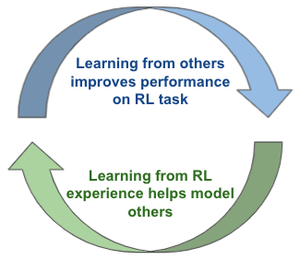
PsiPhi-Learning: Reinforcement Learning with Demonstrations using Successor Features and Inverse Temporal Difference Learning
PsiPhi-Learning learns successor representations for the policies of other agents and the ego agent, using a shared underlying state representation. Learning from other agents helps the agent take better actions at inference time, and learning from RL experience improves modeling of other agents.
A. Filos
,
C. Lyle
,
Y. Gal
,
S. Levine
,
Natasha Jaques
*
,
G. Farquhar
*
2021
In
International Conference on Machine Learning (ICML)
Oral (top 3% of submissions)
PDF
Cite
Project
ICML talk
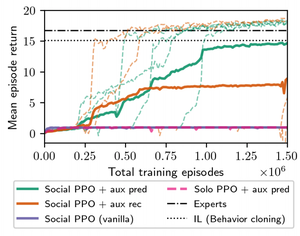
Emergent Social Learning via Multi-agent Reinforcement Learning
Model-free RL agents fail to learn from experts present in multi-agent environments. By adding a model-based auxiliary loss, we induce social learning, which allows agents to learn how to learn from experts. When deployed to novel environments with new experts, they use social learning to determine how to solve the task, and generalize better than agents trained alone with RL or imitation learning.
Kamal Ndousse
,
Douglas Eck
,
Sergey Levine
,
Natasha Jaques
2021
In
International Conference on Machine Learning (ICML);
NeurIPS Cooperative AI Workshop
Best Paper
PDF
Cite
Code
Poster
Slides
Cooperative AI talk
ICML talk
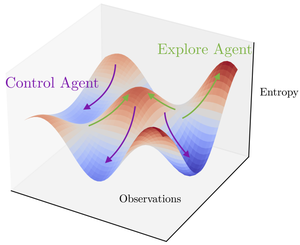
Explore and Control with Adversarial Surprise
Adversarial Surprise creates a competitive game between an Expore policy and a Control policy, which fight to maximize and minimize the amount of entropy an RL agent experiences. We show both theoretically and empirically that this technique fully explores the state space of partially-observed, stochastic environments.
A. Fickinger
*
,
Natasha Jaques
*
,
S. Parajuli
,
M. Chang
,
N. Rhinehart
,
G. Berseth
,
S. Russell
,
S. Levine
2021
In
ICML Unsupervised Reinforcement Learning workshop
PDF
Cite
Code
Project
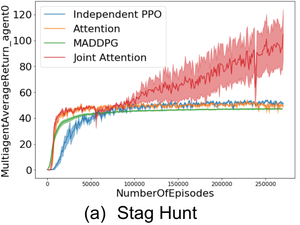
Joint Attention for Multi-Agent Coordination and Social Learning
Joint attention is a critical component of human social cognition. In this paper, we ask whether a mechanism based on shared visual attention can be useful for improving multi-agent coordination and social learning.
D. Lee
,
Natasha Jaques
,
J. Kew
,
D. Eck
,
D. Schuurmans
,
A. Faust
2021
In
ICRA Social Intelligence Workshop
Spotlight talk
PDF
Cite
Code
Poster
Video
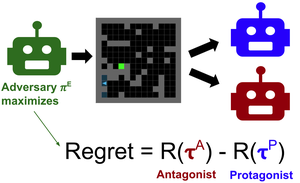
Emergent Complexity and Zero-shot Transfer via Unsupervised Environment Design
PAIRED trains an agent to generate environments that maximize regret between a pair of learning agents. This creates feasible yet challenging environments, which exploit weaknesses in the agents to make them more robust. PAIRED significantly improves generalization to novel tasks.
Michael Dennis
*
,
Natasha Jaques
*
,
Eugene Vinitsky
,
Alexandre Bayen
,
Stuart Russell
,
Andrew Critch
,
Sergey Levine
2020
In
Neural Information Processing Systems (NeurIPS)
Oral (top 1% of submissions)
PDF
Cite
Code
Poster
Slides
Videos
NeurIPS Oral
Science article
Google AI Blog
»
Cite
×