Natasha Jaques
Assistant Professor, University of Washington
Senior Research Scientist, Google DeepMind
Social learning helps humans and animals rapidly adapt to new circumstances, and drives the emergence of complex learned behaviors. My research is focused on Social Reinforcement Learning—developing algorithms that combine insights from social learning and multi-agent training to improve AI agents’ learning, generalization, coordination, and human-AI interaction.
I am an Assistant Professor at the University of Washington Paul G. Allen School of Computer Science & Engineering, where I lead the Social RL Lab. I am also a Senior Research Scientist at Google DeepMind. If you are interested in joining my lab as a PhD student, check out our contact page for more information.
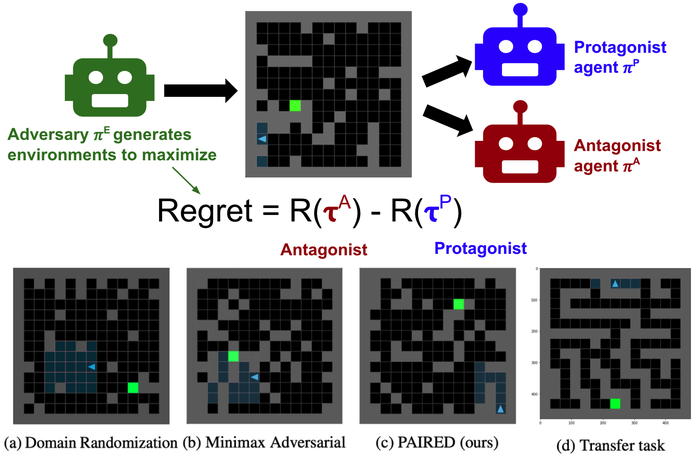
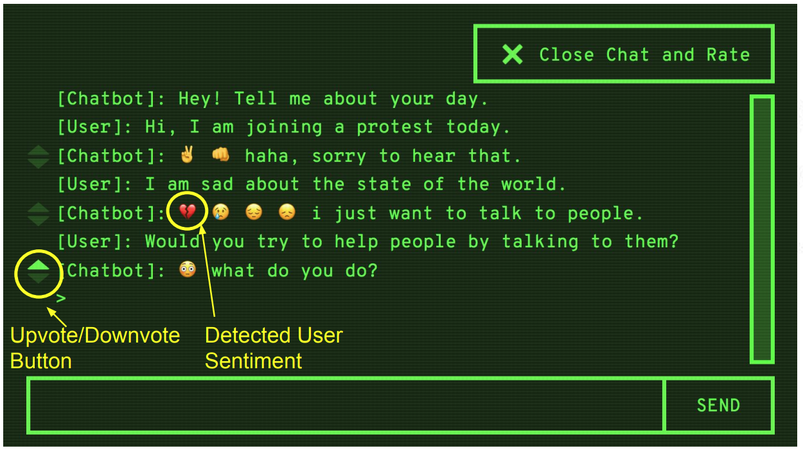
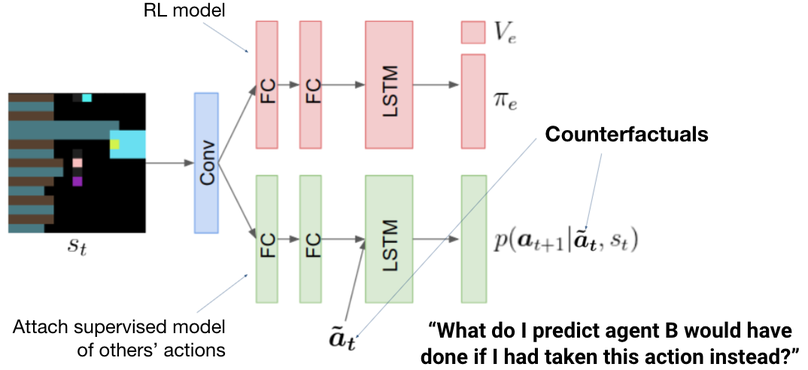
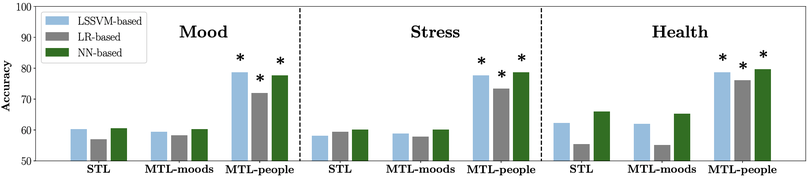
During my PhD at MIT, I developed techniques for fine-tuning language models with RL and learning from human feedback which were later built on by OpenAI’s series of work on Reinforcement Learning from Human Feedback (RLHF) [1,2,3]. In the multi-agent space, I developed techniques for improving coordination through the optimization of social influence. I interned at DeepMind, Google Brain, and was an OpenAI Scholars Mentor. I was subsequently a Visiting Postdoctoral Scholar at UC Berkeley, in Sergey Levine’s group, and a Senior Research Scientist at Google Brain, where I built novel methods for adversarial environment generation to improve the robustness of RL agents. My work has received various awards, including Best Demo at NeurIPS, an honourable mention for Best Paper at ICML, and the Outstanding PhD Dissertation Award from the Association for the Advancement of Affective Computing. My work has been featured in Science Magazine, MIT Technology Review, Quartz, IEEE Spectrum, Boston Magazine, and on CBC radio, among others. I earned a Master's degree from the University of British Columbia, and undergraduate degrees in Computer Science and Psychology from the University of Regina.
Download my CV.-
PhD in the Media Lab, 2019
Massachusetts Institute of Technology
-
MSc in Computer Science, 2014
University of British Columbia
-
BSc in Computer Science, 2012
University of Regina
-
BA in Psychology, 2012
University of Regina
Selected Awards
- 2023 Best Paper at the AAAI Representation Learning for Responsible Human-Centric AI workshop
- 2021 Outstanding PhD Dissertation from the international Association for the Advancement of Affective Computing
- 2021 Best of Collection in the journal IEEE Transactions on Affective Computing (impact factor: 10.5)
- 2020 Best Paper at the NeurIPS Workshop on Cooperative AI
- 2019 Best Paper Honourable Mention at the International Conference on Machine Learning (ICML) 2019
- 2019 Rising Stars in EECS Pitch Competition Winner
- 2019 Best Paper Nominee at the NeurIPS Workshop on Conversational AI
- 2017 Centennial Alumni of Distinction at Campion College
- 2016 Best Paper at the NeurIPS Workshop on ML for Healthcare
- 2016 Best Demo at Neural Information Processing Systems (NeurIPS)
Selected Press
- Degrees Magazine. Cataldo, S. (2021, November 19). The sky’s the limit.
- Science. Hutson, M. (2021, January 19). Who needs a teacher? Artificial intelligence designs lesson plans for itself.
- IEEE Spectrum. Hutson, M. (2019, June 17). DeepMind Teaches AI Teamwork.
- MIT Technology Review. Hao, K. (2019, June 20). Here are 10 ways AI could help fight climate change.
- National Geographic. Snow, J. (2019, July 18). How artificial intelligence can tackle climate change.
- Quartz. Gershgorn, D. (2018, February 16). Google is building AI to make humans smile.
- MIT Technology Review. Knight, W. (2016, November 30). AI songsmith cranks out surprisingly catchy tunes.
- Boston Magazine. Annear, S. (2015, January 5). Website tracks your happiness to remind you life’s not so bad.
- CBC radio. Brace, S. (2015, January 5). Regina woman develops smile app at MIT.
Featured Publications
Publications
To find relevant content, try searching publications, filtering using the buttons below, or exploring popular topics. A * denotes equal contribution.
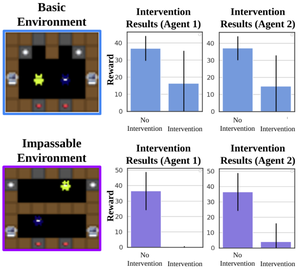
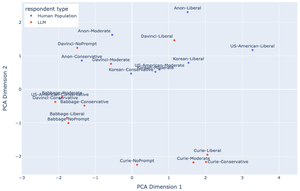
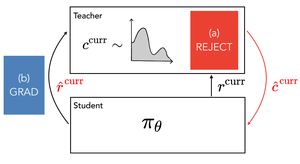
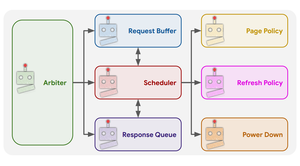
*
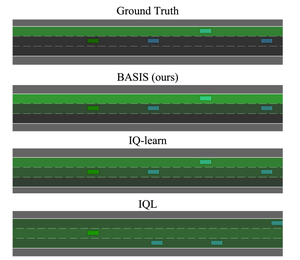
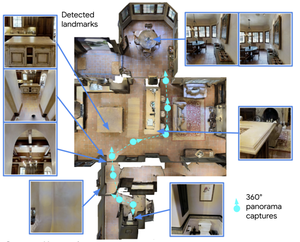
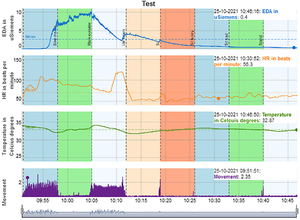
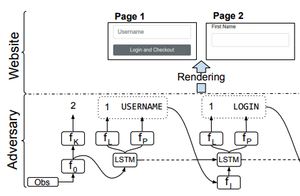
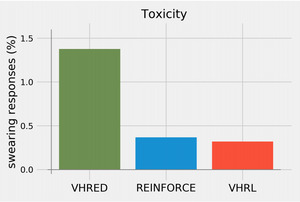
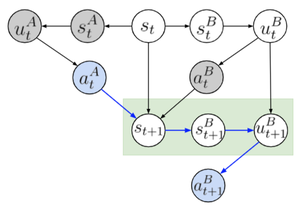
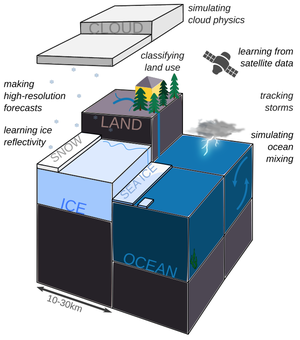
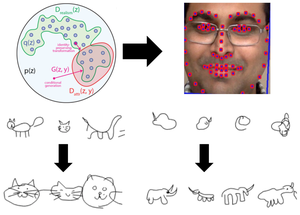
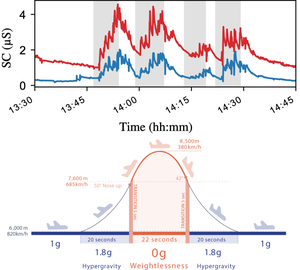
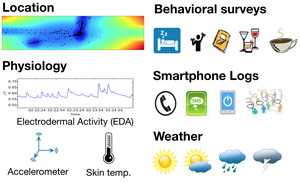
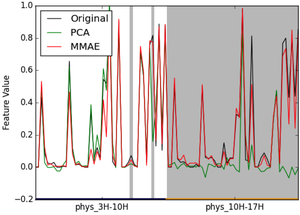
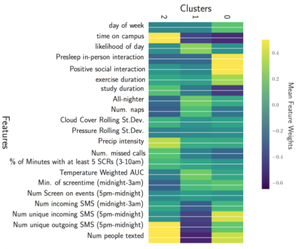
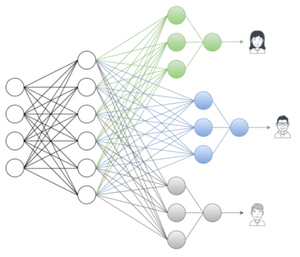
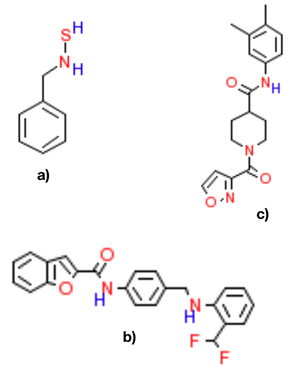


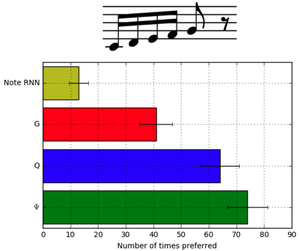
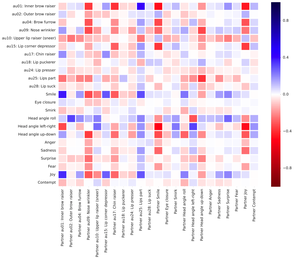
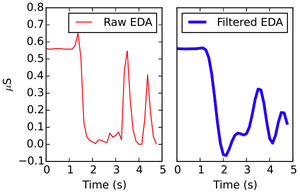
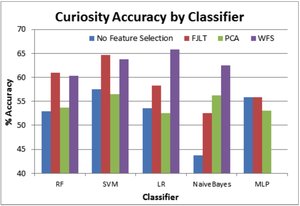
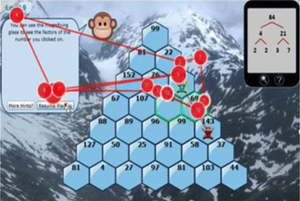
Featured Talks

Research Communities
- Together with Eugene Vinitsky, I run the Berkeley Multi-Agent Reinforcement Learning Seminar, which includes participants from Berkeley, Stanford, Google Brain, OpenAI, Facebook AI Research (FAIR), and other universities.
- Co-organizer of the NeurIPS 2021 Cooperative AI workshop.
- As part of the workshop, I planned and implented a mentorship program to provide feedback on submissions to students from underrepresented groups.
- Panelist and moderator for the NeurIPS 2020 Cooperative AI workshop.
- Co-organizer of the ICLR 2020 Climate Change for Artificial Intelligence (CCAI) workshop.
- Former Social Media Lead for CCAI.
- Co-organizer of the NeurIPS 2019 Emergent Communication (EmeComm) workshop.
- Co-organizer of the ICML 2018 Artificial Intelligence in Affective Computing (AffComp) workshop.